梯度下降
主要目的是通过迭代找到目标函数的最小值,或者收敛到最小值。—-也可参考《An overview of gradient descent optimization algorithms》
基于day1的代价函数,梯度下降就是找到一个方法使得 J 快速由峰值到峰底,例如: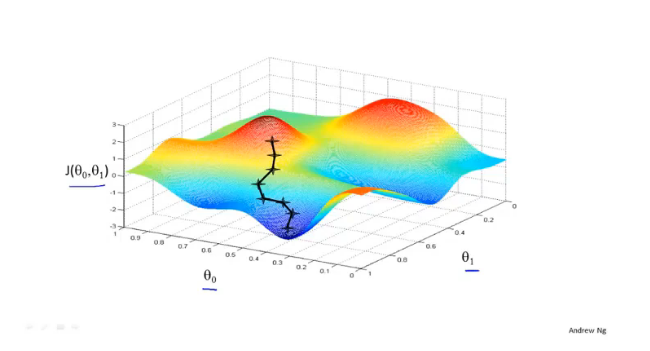
类似下山场景。 —《Gradient Descent - Problem of Hiking Down a Mountain》
算法表示

代码实现
1 | # 定义数据集和学习率 |
结果为:1
2
3optimal: [[0.51583286]
[0.96992163]]
error function: 405.9849624932369
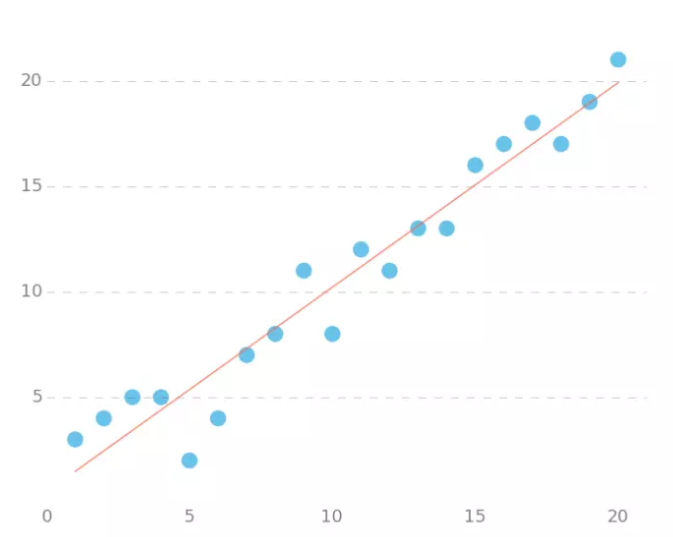
拟合结果为图中直线。
参考: