页面数据分析
获取网站页面信息,首先确定数据位置: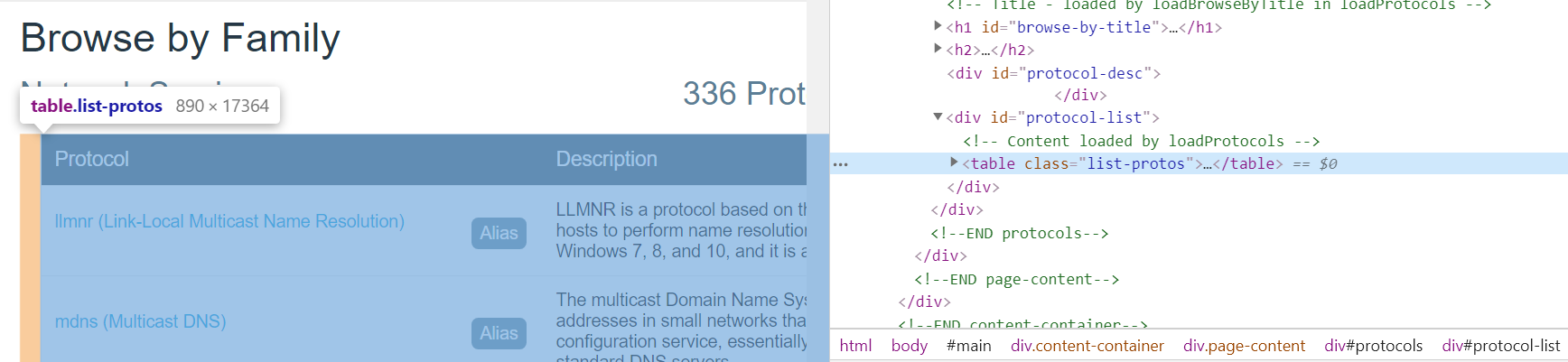
提取列表标签下整个数据块:1
2
3
4
5# 获取列表信息
def get_host_info_list(source):
host_info_list = re.findall('(div id="protocol-list">.*?</div>)', source, re.S)
print(host_info_list)
return host_info_list
处理数据块内部数据,分析1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
通过对标签```goToProtocolRecord```搜索获取对应值:
```python
# 获取具体信息
def get_host_info(host_info):
ret = re.search('<a onclick="goToProtocolRecord(.*?)<', host_info)
if ret is None:
return ""
else:
host_name = str(ret.group(1))
ret2 = re.search('span class="en">(.*?)<', host_info)
if ret2 is None:
return ""
else:
host_desc = str(ret2.group(1))
return host_name+' : '+host_desc
以上是对一个页面内容进行提取,但需要获取多页面的数据时: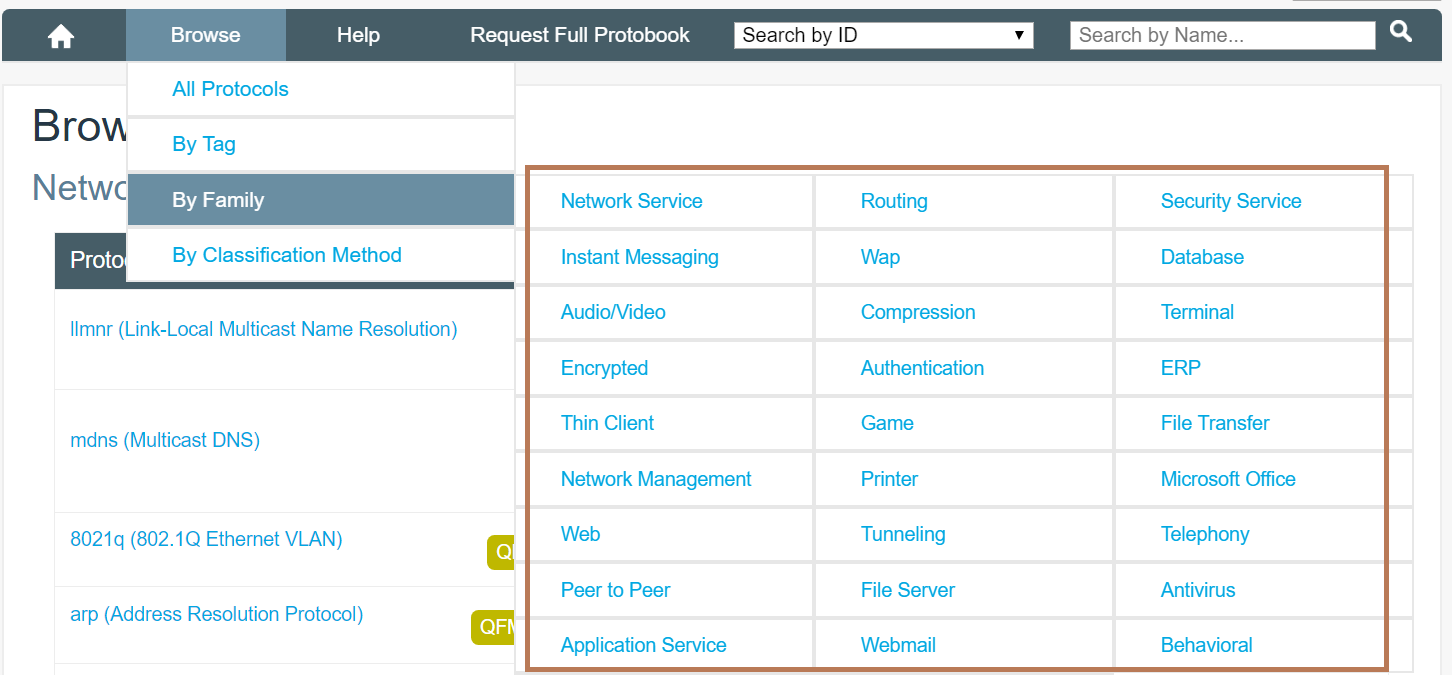
就要构造url进行遍历访问:1
2
3
4
5
6
7def change_page(url, total_page):
cur_page = int(re.search('index_.*?_(\d)*', url).group(1))
all_pages = []
for i in range(cur_page, total_page + 1):
all_pages.append(re.sub('_\d', 'index_%s' % i, url, re.S))
print(all_pages)
return all_pages
url 请求的过程
用request进行请求访问,获取应答数据:1
2
3
4
5
6
7
8def request_url(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
with request.urlopen(req) as f:
data = f.read()
time.sleep(0.01)
return data
结果
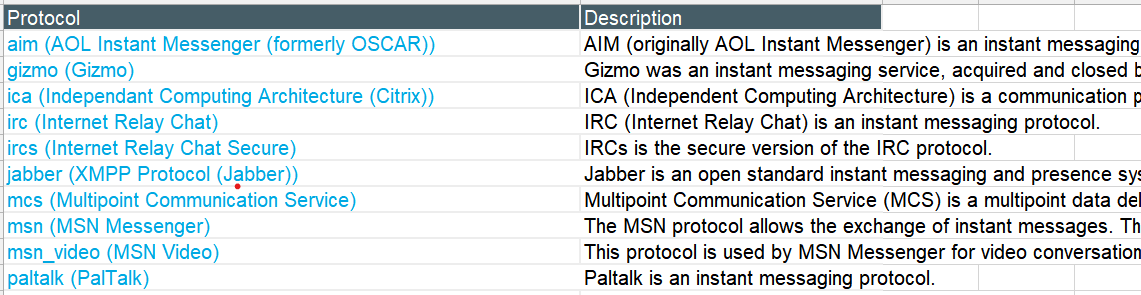
也可以使用BeautifulSoup,进行request访问后,使用BeautifulSoup提取
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'按分类爬取web info'
__author__ = 'hj he'
import re
from urllib import request
import urllib.request
import io
import sys
import time
# 获取列表信息
def get_host_info_list(source):
host_info_list = re.findall('(div id="protocol-list">.*?</div>)', source, re.S)
print(host_info_list)
return host_info_list
# 获取具体信息
def get_host_info(host_info):
ret = re.search('<a onclick="goToProtocolRecord(.*?)<', host_info)
if ret is None:
return ""
else:
host_name = str(ret.group(1))
ret2 = re.search('span class="en">(.*?)<', host_info)
if ret2 is None:
return ""
else:
host_desc = str(ret2.group(1))
return host_name+' : '+host_desc
def request_url(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
with request.urlopen(req) as f:
data = f.read()
time.sleep(0.01)
return data
def change_page(url, total_page):
cur_page = int(re.search('index_.*?_(\d)*', url).group(1))
all_pages = []
for i in range(cur_page, total_page + 1):
all_pages.append(re.sub('_\d', 'index_%s' % i, url, re.S))
print(all_pages)
return all_pages
def text_read(filename):
# Try to read a txt file and return a list.Return [] if there was a mistake.
try:
file = open(filename,'r')
except IOError:
error = []
return error
content = file.readlines()
for i in range(len(content)):
content[i] = content[i][:len(content[i])-1]
file.close()
return content
def save_info(info):
with open('qosmos_falmily_res.txt', 'a', encoding='utf-8') as f:
for i in info:
f.write(i + '\n')
def getUrl_multiTry(url):
user_agent = '"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2125.122 Safari/539.36"'
headers = {'User-Agent': user_agent}
maxTryNum = 3
for tries in range(maxTryNum):
try:
req = urllib.request.Request(url, headers=headers)
with request.urlopen(req) as f:
return f.read()
except Exception as e:
if tries < (maxTryNum - 1):
print(url)
print('request again\n')
'''continue'''
else:
#logging.error("Has tried %d times to access url %s, all failed!", maxTryNum, url)
print('except:', e)
'''break'''
if __name__ == '__main__':
familyList = text_read('qosmos_family.txt')
for family in familyList:
familyUrl = "https://protobook.qosmos.com/browse_protocols.html?type=Family&value=" + family
info_list = []
#url = countryUrl + ".html"
data = getUrl_multiTry(familyUrl)
host_info_list = get_host_info_list(data.decode('utf-8'))
for host_info in host_info_list:
info_list.append(family+":"+get_host_info(host_info))
save_info(info_list)
#print(info_list)
del info_list[:]